
When dealing with high-velocity data ingestion, specifically from streaming sources like Kafka, Apache Druid users often face a silent performance killer: segment fragmentation. As data streams in, it often arrives in small, discontinuous pieces, creating thousands of tiny files that clog the system. This acts like a library where every sentence is written on a separate strip of paper rather than bound in a book—retrieving the full story requires immense effort.
This is where compaction comes in. Far more than a simple cleanup script, compaction is a sophisticated, background ingestion task that merges, optimizes, and refines data to keep query speeds sub-second.
As of Wednesday, February 4, 2026, understanding how to configure this process is essential for reducing storage costs and maintaining cluster stability.
Listen to the episode
How Druid Compacts Raw Events: A Step-by-Step Guide
The problem: Segment fragmentation
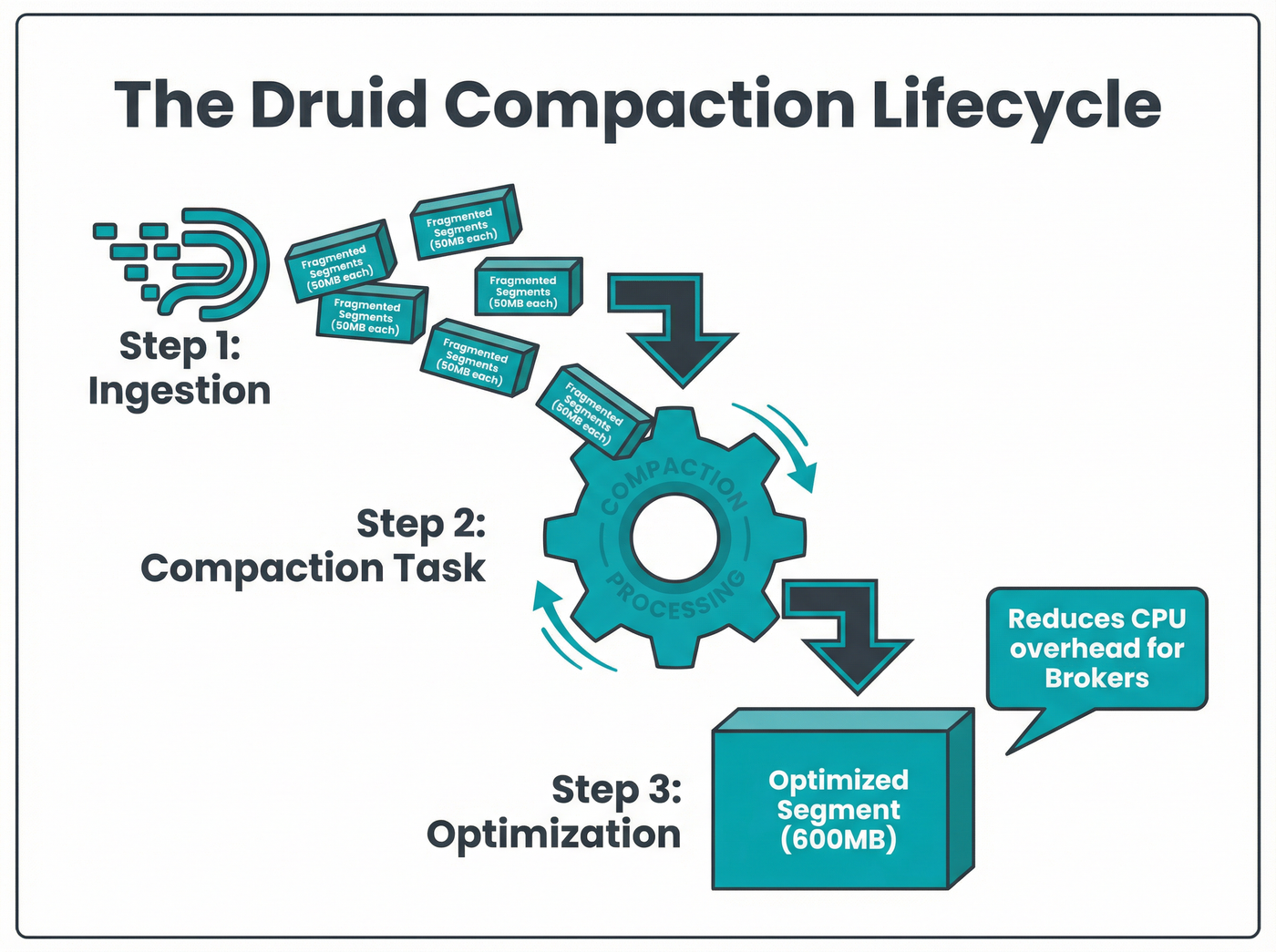
In Apache Druid, the fundamental unit of storage is the segment—a time-partitioned file that dictates how quickly a query can scan and filter data. However, real-time ingestion generally results in "best-effort" rollup. Data arrives a little bit at a time, forcing Druid to create many small segments for the same time interval.
This fragmentation forces the Broker and Historical processes to hunt through excessive files to answer a single query. Without intervention, the CPU cycles wasted on merging partial results from these micro-segments can cripple system responsiveness.[1]
How compaction works
Compaction acts as a background defragmentation process. It reads the existing set of segments for a given time interval and combines the data into a new, "compacted" set. The primary goal is to reach a target segment size, which best practices suggest lies between 300MB and 700MB.[4]
This "sweet spot" ensures the segment is large enough to benefit from columnar compression but small enough to be scanned rapidly in parallel across the cluster. If segments become too large (e.g., exceeding 5GB), they can create distribution issues where specific Historical nodes become hot spots.
Secondary refinement: Saving space and money
Beyond simply merging files, compaction offers a strategic opportunity for secondary refinement. You can modify the data structure during this process to drastically reduce storage footprint—often by 30% to 50%—without losing critical insights.
Perfect rollup
Streaming ingestion performs best-effort rollup, meaning it aggregates data as it arrives but cannot guarantee perfect compaction due to late-arriving events. Compaction tasks can re-process this data to achieve perfect rollup, maximizing aggregation and shrinking the total row count.[1]
Coarser granularity
For historical analysis, minute-by-minute detail is often unnecessary. Compaction allows engineers to change the query granularity for older data. For example, you can retain full fidelity for the last 30 days but collapse data older than a year from hourly to daily segments. This reduces the number of rows significantly, lowering costs on deep storage (like S3) and improving query performance for long-range analytics.
Manual vs. Automatic Compaction
Operators must decide how to trigger these tasks. Druid supports both manual and automatic methods, each suited for specific scenarios.
Automatic Compaction (Auto-compaction)
For most production workloads, automatic compaction is the standard. Managed by the Coordinator, this system continuously monitors segments and launches tasks to fix those that are sub-optimal.[2]
Included in the auto-compaction configuration is the ability to set a skip offset. This ensures the system does not attempt to compact data that is still actively being written to by real-time tasks, avoiding write-contention conflicts.[5]

Manual Compaction
Manual compaction is typically a one-off event used for administrative overhauls. You might use the manual API to:
- Force a massive re-indexing of historical data.
- Implement schema changes, such as removing an unused column from years of data.
- Change partitioning schemes that auto-compaction logic cannot easily handle.
While powerful, manual tasks require careful resource management to avoid starving the cluster of ingestion slots.[1]
Conclusion
Compaction is not just about keeping your file system tidy; it is a critical lever for performance tuning and cost control in big data architecture. By utilizing auto-compaction for daily maintenance and leveraging secondary refinement for historical data, organizations can ensure their Apache Druid clusters remain fast and efficient.